

近年、大規模 言語モデル(LLM) は、 自然言語処理(NLP) の世界に革命をもたらしました 。
かつては翻訳、要約、質疑応答など、タスクごとに専用のモデルが必要でしたが、今やLLMという単一の汎用基盤モデルが、 プロンプト(指示) だけで多様なタスクをこなします 。
では、マシンビジョン(コンピュータが画像を理解する技術)の世界ではどうでしょうか?
現在、セグメンテーション(領域分割)には「 Segment Anything 」 、物体検出には YOLO のように、優れたタスク専用モデルが存在しています。
しかし、LLMがNLPで起こしたような「汎用モデルへの統一」は、ビジョン分野でも起こり得るのでしょうか?
Google DeepMind による最新の研究論文「 Video models are zero-shot learners and reasoners (ビデオモデルはゼロショット学習者であり推論者である)」は、この問いに「イエス」と力強く答えています。
本論文は、最新のビデオモデル「 Veo 3 」が、明示的に訓練されていない驚くほど多様なタスクをゼロショット(追加学習なし)で解決できることを実証しています。
この記事では、Veo 3がどのようにしてタスク固有モデルの壁を越え、汎用的な「視覚基盤モデル」への道を切り開いているのか、その驚異的な能力をご紹介します。
Veo 3が示す4つの階層的な能力
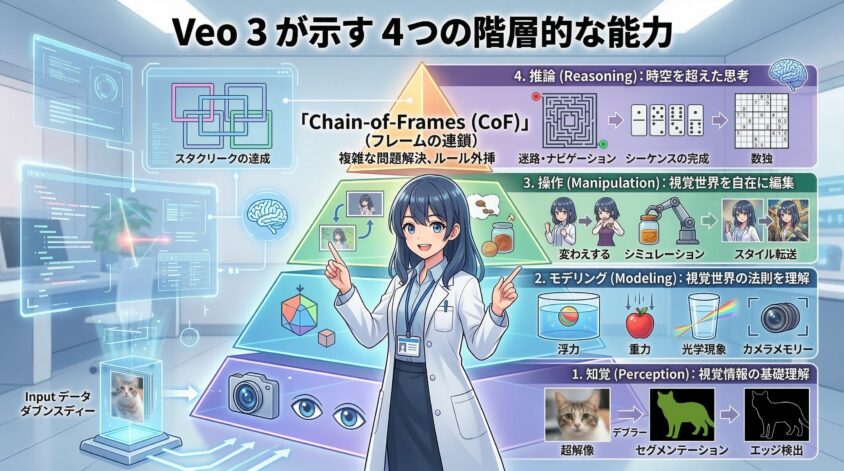
研究チームは、Veo 3の能力を「知覚」「モデリング」「操作」「推論」という4つの階層で整理し、62の質的タスクと7つの量的タスクでその性能を分析しました。
1. 知覚 (Perception): 視覚情報の基礎理解
これは、モデルが視覚情報をどれだけ正確に理解できるかという基盤的な能力です。Veo 3は、プロンプト(テキスト指示)だけで、これまで専用モデルが必要だった古典的なコンピュータビジョンタスクを実行できます。
- エッジ検出
- セグメンテーション(物体の領域分割)
- キーポイント(特徴点)の特定
- 超解像(画像の高画質化)
- ブラインド・デブラーリング(ぼかし除去)
- ノイズ除去
これらはビデオモデルの訓練タスク(動画生成)とは直接関係ないにもかかわらず、Veo 3はこれらの能力をゼロショットで獲得していることが示されました。
2. モデリング (Modeling): 視覚世界の法則を理解する
知覚した情報に基づき、Veo 3は私たちが住む世界の物理的な法則や関係性をモデル化し始めています。
- 直感的な物理法則: 物体の浮力(水に浮くか沈むか)、空気抵抗(地球上と月面での落下の違い)、剛体と軟体(布)の動きなどを理解している様子が示されました。
- 光学現象: ガラスの屈折や鏡の反射を正しく生成します。
- 抽象的な関係性: 「おもちゃ」と「ラップトップ」を区別し、プロンプトに応じておもちゃだけをバケツに入れるといったタスクも可能です。
- 世界の記憶: カメラがズームインした後、ズームアウトして元の視点に戻るといった、ビデオコンテキスト内での世界の状態を記憶しています。
3. 操作 (Manipulation): 視覚世界を自在に編集する
Veo 3は、世界を認識しモデル化するだけでなく、プロンプトに応じてその世界を能動的に操作(編集)できます。
- 画像編集: 背景の除去、スタイルの転送(例:写真を特定の画家の作風に)、カラー化、インペインティング(一部の修復)、アウトペインティング(画像の続きを描画)などをゼロショットで実行します。
- 3Dアウェアな操作: オブジェクトの新しい視点を生成したり、キャラクターのポーズを変更したり、セルフィーをプロフェッショナルなヘッドショット(証明写真風)に変換したりできます。
- シミュレーション: ロボットハンドによる器用な瓶開けや、ブリトーの巻き方をシミュレートすることも可能です。
4. 推論 (Reasoning): 時空を超えたステップバイステップの思考
そして最も注目すべきは、これら「知覚」「モデリング」「操作」の能力を統合し、初期段階の「視覚的推論」を実行できる点です。
研究チームは、LLMが「Chain-of-Thought (CoT)」(思考の連鎖)によって複雑な問題をステップバイステップで解く能力を獲得したことになぞらえ、ビデオモデルがビデオ生成(フレームごとの処理)を通じて行う視覚的推論を「Chain-of-Frames (CoF)」(フレームの連鎖)と名付けました。
Veo 3は、このCoFの初期形態を以下のタスクで示しています。
- 迷路・ナビゲーション: 迷路のスタート(赤い円)からゴール(緑の円)まで、壁を越えずに正しく移動する経路を生成できます。
- シーケンス(数列)の完成: ドミノのドットや矢印の向きなど、特定のルールを持つシーケンスの続きを正しく予測して描画します。
- パズル: 簡単な数独や、同じ色の円同士を線で結ぶパズルを解きます。
- ルールの外挿: 示された例から視覚的なルールを抽出し、新しいグリッドに適用します。
Veo 2からVeo 3への飛躍的な進化

この研究の説得力を高めているのが、旧モデル「 Veo 2 」と「Veo 3」の直接比較です。Veo 2の発表からVeo 3の発表まで(2024年12月~2025年5月)は半年ほどしかありませんが、その性能は劇的に向上しています。
例えば、定量的に評価された7つのタスクにおいて、Veo 3はVeo 2を一貫して大幅に上回っています。
- エッジ検出 (図3): Veo 3 (0.77 OIS@10) は Veo 2 (0.57 OIS@10) より遥かに優れています。
- セグメンテーション (図4): Veo 3 (0.74 mIoU@10) は Veo 2 (0.52 mIoU@10) を凌駕しています。
- 動物の抽出 (図5): Veo 2がほぼチャンスレベル(当てずっぽう)だったのに対し、Veo 3は最大93% (pass@10) の精度を達成しました。
- 迷路解決 (図7): 5×5の単純な迷路でさえ、Veo 2の成功率が14% (pass@10) だったのに対し、Veo 3は78% (pass@10) を達成しました。
この急速な進歩は、ビデオモデルの能力がまだ発展途上であり、今後さらに強力になることを示唆しています。
結論:マシンビジョンの「GPT-3モーメント」は近いか?

本論文は、Veo 3が持つ広範なゼロショット能力こそ、マシンビジョンがLLMのような汎用基盤モデルへと向かう「パラダイムシフトの兆候」であると結論づけています。
もちろん、Veo 3はまだ完璧ではありません。
多くのタスクで専門モデルの性能には及ばず、失敗するケース(例:複雑な物理パズルやモーションプランニング)も報告されています。
しかし研究者らは、これはLLMの初期段階(例:GPT-3)が、多くのタスクでファインチューニングされた専用モデルに劣っていた状況と酷似していると指摘します。
現在のビデオモデルの性能は、あくまで「下限」に過ぎません。
プロンプトの工夫(視覚的なプロンプトを含む)次第で、性能はさらに向上する可能性があります。
また、現在は高価なビデオ生成コストも、LLMの推論コストが劇的に低下したように、いずれ解決されると予測されています。
Veo 3が示した「Chain-of-Frames」による視覚的推論は、まだ初期段階です。
しかし、この能力が成熟していけば、ビデオモデルは単に「見る」だけでなく、視覚世界について「考え、計画し、実行する」ための統一された基盤モデルとなるでしょう。
マシンビジョンの未来に、非常にエキサイティングな時が訪れています。
出典:
Wiedemer, T., Li, Y., Vicol, P., Gu, S. S., Matarese, N., Swersky, K., Kim, B., Jaini, P., & Geirhos, R. (2025). Video models are zero-shot learners and reasoners. arXiv:2509.20328v2 [cs.LG]. 63636363プロジェクトページ: https://video-zero-shot.github.io/ 64